大模型竞争白热化!智谱、MiniMax密集发布,DeepSeek V4路线图曝光
2月11日晚间,智谱发布新一代旗舰模型GLM-5,智谱称,GLM-5在Coding与Agent能力上,取得开源SOTA表现,在真实编程场景的使用体感逼近Claude Opus 4.5,擅长复杂系统工程与长程Agent任务。
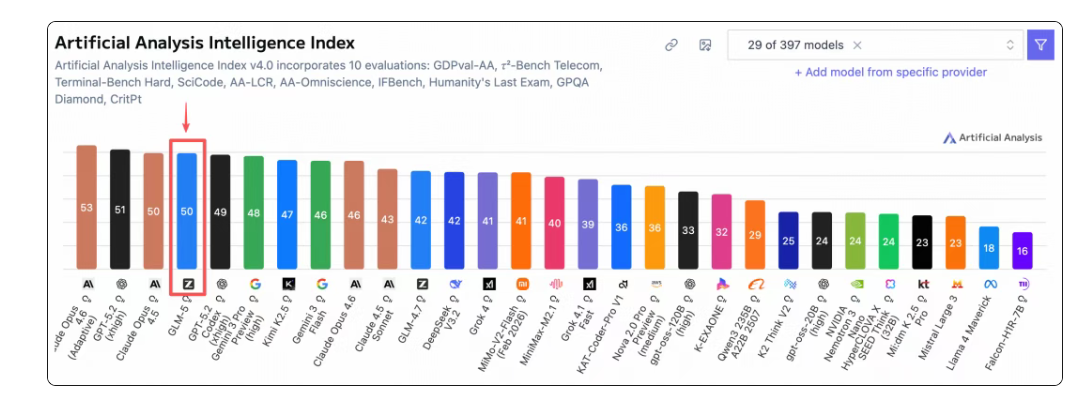
智谱宣布,在全球权威的 Artificial Analysis 榜单中,GLM-5 位居全球第四、开源第一。GLM-5拥有744B(激活 40B)参数模型,预训练数据从 23T 提升至 28.5T,更大规模的预训练算力显著提升了模型的通用智能水平。
GLM-5构建全新的“Slime”框架,支持更大模型规模及更复杂的强化学习任务,提升强化学习后训练流程效率;提出异步智能体强化学习算法,使模型能够持续从长程交互中学习,充分激发预训练模型的潜力。在稀疏注意力机制方面,GLM-5首次集成 DeepSeek Sparse Attention,在维持长文本效果无损的同时,大幅降低模型部署成本,提升 Token Efficiency。
智谱称,GLM-5在编程能力上实现了对Claude Opus 4.5的对齐,在主流基准测试中取得开源模型SOTA分数。在SWE-bench-Verified和Terminal Bench 2.0中,GLM-5分别获得77.8和56.2的开源模型SOTA分数,性能超过Gemini 3 Pro。
GLM 系列模型受到全球开发者喜爱,在 GLM Coding Plan 全球爆量后,智谱公司不得不启动限售活动。值得关注的是,GLM系列已经完成已完成与华为昇腾、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光等国产算力平台的深度推理适配。通过底层算子优化与硬件加速,GLM-5 在国产芯片集群上已经实现高吞吐、低延迟的稳定运行。
2月12日,MiniMax宣布上线最新旗舰编程模型MiniMax M2.5,目前在模型界面已经可以选择调用。据官方介绍,这是一个为智能体场景原生设计的生产级模型,其编程与智能体性能对标国际顶尖模型Claude Opus 4.6,支持PC、App、跨端应用的全栈编程开发,尤其适配 Excel高阶处理、深度调研、PPT等生产力场景。M2.5模型激活参数量为10B,在显存占用和推理能效比上有优势,推理速度超过国际顶尖模型。
预计2月中旬,DeepSeek将会发布新一代旗舰大模型V4,根据近期由创办人梁文锋署名的论文及业内爆料,V4 将引入 mHC 与 Engram 两项核心架构创新,旨在显著降低训练与推理成本,并在编程能力上挑战目前的行业领导者。
在DeepSeek团队在最新发布的论文中提出,当前模型缺乏原生的知识查找机制,导致在处理静态知识时仍需耗费昂贵的算力重复推导。为此,V4 预计将引入 Engram(条件记忆模块),其设计理念是将“记忆”与“计算”解耦。
透过 Engram 技术,模型能将静态知识 (如实体、固定表达) 存储在廉价的 DRAM 中,而非昂贵的 GPU 高带宽内存 (HBM)。当模型需要推理时再快速查找,这将释放 GPU 算力专注于复杂的动态计算。此外,另一项关键技术 mHC(流形约束超连接) 则解决了超深层 Transformer 模型在训练时,信息流动瓶颈与不稳定的问题,透过严苛的数学「护栏」,提升模型在数学推理等任务上的表现。
据 美国The Information 报导,DeepSeek V4 的内部初步测试显示,其编程能力已超越市场上的顶级模型,包括 OpenAI 的 GPT 系列与 Anthropic 的 Claude。尽管 DeepSeek 先前推出的 V3.2 版本已在多项基准检验中超越部分竞争对手,但 V4 被视为核心架构的正式继任者,旨在进一步巩固其作为高性能、低成本 AI 方案的地位。
当下,大模型的竞争已经从卷开源社区,走向争夺AI时代入口的升级阶段。智谱此次发布新模型之后,大幅提价,说明国产模型的技术能力和市场竞争力明显提升。在大模型从“技术竞赛”转向“商业兑现”的关键阶段,谁能通过开源构建起活跃的开发者生态,并将其转化为可持续的收入流,谁才真正赢得下一阶段。
- 5年卖了80万台后,零跑全新C系列继续“自我革命”
- 【盖世快讯】比亚迪交付英国第10万台新能源车;传鸿蒙智行全面引入电池二供
- 月薪从2.6万跌到700,超10万“4S人”无奈离场,4S模式真走到尽头了?
- 宁德时代新设全资新能源企业 布局储能相关业务
- RTA Fleet推出Ron360 将对话式AI直接引入车队管理工作流程
- 出口增长翻倍,2026年1-5月新能源汽车累计销售580.2万辆
- 全链车规实力护航 湖北优炜芯车载制氧机成为新能源车企定点优选 打造医疗级健康座舱标杆
- 东芝推出新款40V N沟道功率MOSFET 提升汽车应用的效率
- 中国汽车,何时放弃自封为王
- 比亚迪匈牙利工厂将于今年第四季度投产
- 比亚迪大唐6月17日上市
- 传比亚迪在加拿大启动管理岗招聘
- 长城汽车5月销量超10万辆
- 5月汽车保值率:车源多了,但价格跌了
- 展望十五五|我国汽车产业进入“由大到强”的决胜期——第三十三届中国汽车工程学会年会暨展览会新闻发布会在京举行
- 图尔库大学开发出新型智能材料 可使汽车天窗储存太阳能并按需变换颜色